最近很火的人工智能AI助手——deepseek中文版,能让用户在线开展趣味十足的对话与问答;只需输入几个关键词和设定角色,它还能自动生成文章。这款软件支持多账号同时登录,所有记录和数据都会同步,有需求的用户可直接使用。
DeepSeek API 采用与 OpenAI 兼容的 API 格式,您只需调整相关配置,就能借助 OpenAI SDK 调用 DeepSeek API,也可使用支持 OpenAI API 兼容的各类软件。

* 出于与 OpenAI 兼容考虑,您也可以将 base_url 设置为 https://api.deepseek.com/v1 来使用,但注意,此处 v1 与模型版本无关。
* deepseek-chat 模型已全面升级为 DeepSeek-V3,接口不变。 通过指定 model=\'deepseek-chat\' 即可调用 DeepSeek-V3。
调用对话 API
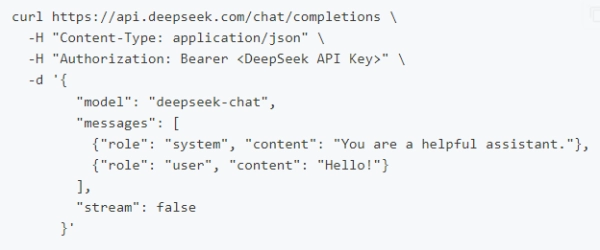
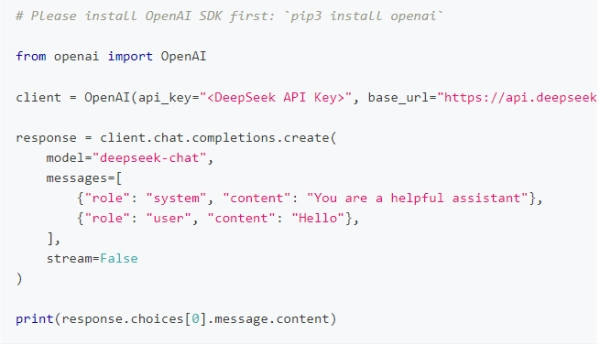
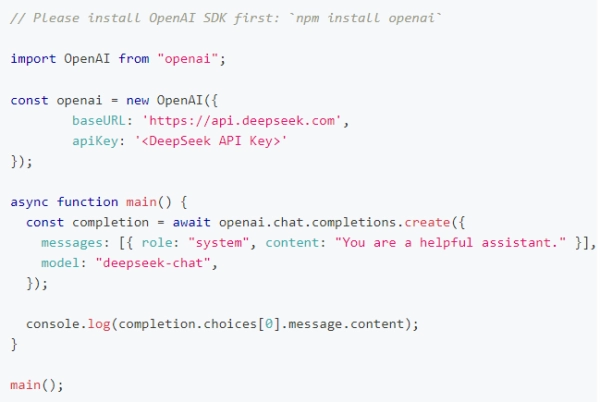
在创建 API key 之后,你可以使用以下样例脚本的来访问 DeepSeek API。样例为非流式输出,您可以将 stream 设置为 true 来使用流式输出。
curl
python
nodejs
DeepSeek-V3已正式推出
今天(2024/12/26),我们全新系列模型 DeepSeek-V3 首个版本上线并同步开源。
登录 chat.deepseek.com 即可与最新版 V3 模型对话。API 服务已同步更新,接口配置无需改动。当前版本的 DeepSeek-V3 暂不支持多模态输入输出。
性能对齐海外领军闭源模型
DeepSeek-V3 为自研 MoE 模型,671B 参数,激活 37B,在 14.8T token 上进行了预训练。
论文链接:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
DeepSeek-V3 多项评测成绩超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他开源模型,并在性能上和世界顶尖的闭源模型 GPT-4o 以及 Claude-3.5-Sonnet 不分伯仲。
● 百科知识: DeepSeek-V3 在知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平相比前代 DeepSeek-V2.5 显著提升,接近当前表现最好的模型 Claude-3.5-Sonnet-1022。
● 长文本: 在长文本测评中,DROP、FRAMES 和 LongBench v2 上,DeepSeek-V3 平均表现超越其他模型。
● 代码: DeepSeek-V3 在算法类代码场景(Codeforces),远远领先于市面上已有的全部非 o1 类模型;并在工程类代码场景(SWE-Bench Verified)逼近 Claude-3.5-Sonnet-1022。
● 数学: 在美国数学竞赛(AIME2025, MATH)和全国高中数学联赛(CNMO2025)上,DeepSeek-V3 大幅超过了所有开源闭源模型。
● 中文能力: DeepSeek-V3 与 Qwen2.5-72B 在教育类测评 C-Eval 和代词消歧等评测集上表现相近,但在事实知识 C-SimpleQA 上更为领先。
生成速度提升至 3 倍
通过算法和工程上的创新,DeepSeek-V3 的生成吐字速度从 20 TPS 大幅提高至 60 TPS,相比 V2.5 模型实现了 3 倍的提升,为用户带来更加迅速流畅的使用体验。
开源权重和本地部署
DeepSeek-V3 采用 FP8 训练,并开源了原生 FP8 权重。
得益于开源社区的支持,SGLang 和 LMDeploy 第一时间支持了 V3 模型的原生 FP8 推理,同时 TensorRT-LLM 和 MindIE 则实现了 BF16 推理。此外,为方便社区适配和拓展应用场景,我们提供了从 FP8 到 BF16 的转换脚本。
模型权重和更多本地部署信息请参考:
https://huggingface.co/deepseek-ai/DeepSeek-V3-Base
V3模型和R1系列模型都是基于V3模型的更基础版本V3-Base开发的。相较于V3(类4o)模型,R1(类o1)系列模型进行了更多自我评估、自我奖励式的强化学习作为后训练。
在R1之前,业界大模型普遍依赖于RLHF(基于人类反馈的强化学习),这一强化学习模式使用了大量由人类撰写的高质量问答以了解「什么才是好的答案」,帮助模型在奖励不明确的情况下知道如何作困难的选择。正是这项技术的使用使得GPT-3进化成了更通人性的GPT-3.5,制造了2022年年底ChatGPT上线时的惊喜体验。不过,GPT的不再进步也意味着这一模式已经到达瓶颈。
R1系列模型放弃了RLHF中的HF(human feedback,人类反馈)部分,只留下纯粹的RL(强化学习)。在其首代版本R1-Zero中,DeepSeek相当激进地启动了如下强化学习过程:为模型设置两个奖励函数,一个用于奖励「结果正确」的答案(使用外部工具验证答案的最终正确性),另一个奖励「思考过程正确」的答案(通过一个小型验证模型评估推理步骤的逻辑连贯性);鼓励模型一次尝试几个不同的答案,然后根据两个奖励函数对它们进行评分。
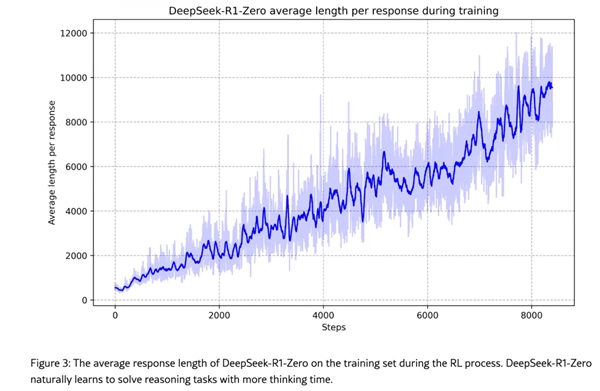
DeepSeek称,R系列模型在强化学习中涌现出了「反思」能力。
DeepSeek发现,由此进入强化学习过程的R1-Zero生成的答案可读性较差,语言也常常中英混合,但随着训练时间增加,R1-Zero能不断「自我进化」,开始出现诸如「反思」这样的复杂行为,并探索解决问题的替代方法。这些行为都未曾被明确编程。
DeepSeek称,这种「啊哈时刻」出现在模型训练的中间阶段。在此阶段,DeepSeek-R1-Zero通过重新评估其初始方法来学习分配更多的思考时间。「这一刻彰显了强化学习的力量和美妙——只要提供正确的激励,模型会自主开发高级解决问题的策略。」DeepSeek称,经过数千个这样的「纯强化学习」步骤,DeepSeek-R1-Zero在推理基准测试中的性能就与OpenAI-o1-0912的性能相匹配了。
DeepSeek在论文中说,「这是第一个验证LLMs的推理能力可以纯粹通过RL(强化学习)来激励,而不需要SFT(supervised fine-tuning,基于监督的微调)的开放研究。」
不过,由于纯强化学习训练中模型过度聚焦答案正确性,忽视了语言流畅性等基础能力,导致生成文本中英混杂。为此DeepSeek又新增了冷启动阶段——用数千条链式思考(CoT)数据先微调V3-Base模型,这些数据包含规范的语言表达和多步推理示例,使模型初步掌握逻辑连贯的生成能力;再启动强化学习流程,生成了大约60万个推理相关的样本和大约20万个与推理无关的样本,将这80万个样本数据再次用于微调V3-Base后,就得到了R1——前面提到,DeepSeek还用这80万个以思维链为主的数据微调了阿里巴巴的Qwen系列开源模型,结果表明其推理能力也提升了。
智能对话
高智商模型,顺滑对话体验
深度思考
先思考后回答,解决推理难题
AI 搜索
全网搜索,信息实时掌握
文件上传
阅读长文档,高效提取信息
准确翻译:提供准确流畅的翻译服务,帮助用户轻松融入多语言环境。
智能解题:解决理科难题,提供详细的解题思路和步骤,帮助用户抓住重点,深入理解。
文件解读:用户可以将文献书籍、资料报告等上传给DeepSeek,会帮助梳理重点,快速理解。
创意写作:根据指令自动生成创意文案,撰写各类文章和报告,快速构建内容框架,提升工作效率。
高效编程:兼容多种编程语言,助力快速排查问题、生成代码,有效提升编程效率。
支持多语言及应用内语言选择。
支持应用内亮色/暗色模式切换。
支持深度思考与搜索同时开启。
软件中的所有对话和问答都是非常智能的,并且还会及时更新




















 3DM正版
3DM正版 生命倒计时安卓免费版
生命倒计时安卓免费版 问小白2026无广告版
问小白2026无广告版 潮音乐官方版
潮音乐官方版 心动劲舞团官方正版
心动劲舞团官方正版 轻微课正版
轻微课正版 苏周到一码通通用版
苏周到一码通通用版 耳机大家坛安卓版
耳机大家坛安卓版 unblockcn安卓免费版
unblockcn安卓免费版 九酷音乐盒免费版
九酷音乐盒免费版 静读天下阅读通用版
静读天下阅读通用版


